Integration of LVM with Hadoop

In this blog, we are going to do two things:
🔅Integrating LVM with Hadoop and providing Elasticity to DataNode Storage
🔅Increase or Decrease the Size of Static Partition in Linux.
LVM (Logical Volume Manager)
Logical volume management (LVM) is a form of storage virtualization that offers system administrators a more flexible approach to managing disk storage space than traditional partitioning.
This type of virtualization tool is located within the device driver stack on the operating system.
It works by chunking the physical volumes (PVs) into physical extents (PEs). The PEs are mapped onto logical extents (LEs) which are then pooled into volume groups (VGs). These groups are linked together into logical volumes (LVs) that act as virtual disk partitions and that can be managed as such by using LVM.
LVM is an amazing technique using which you can increase the storage of device on the fly, without loosing data, without shutting down the system or unmounting the device. Also you can combine two devices to form one single drive.
Lets move to the practical part:
Step 1 : Create LVM Partition
For this, I've created two HD on my LINUX OS, sdb and sdc with sizes 50Gib and 10Gib respectively and created partitions on them.
Then created pv(physical volume) on both.

Using pvdisplay command, we can check details of pv(physical volume) created.

Then created vg(volume group) :

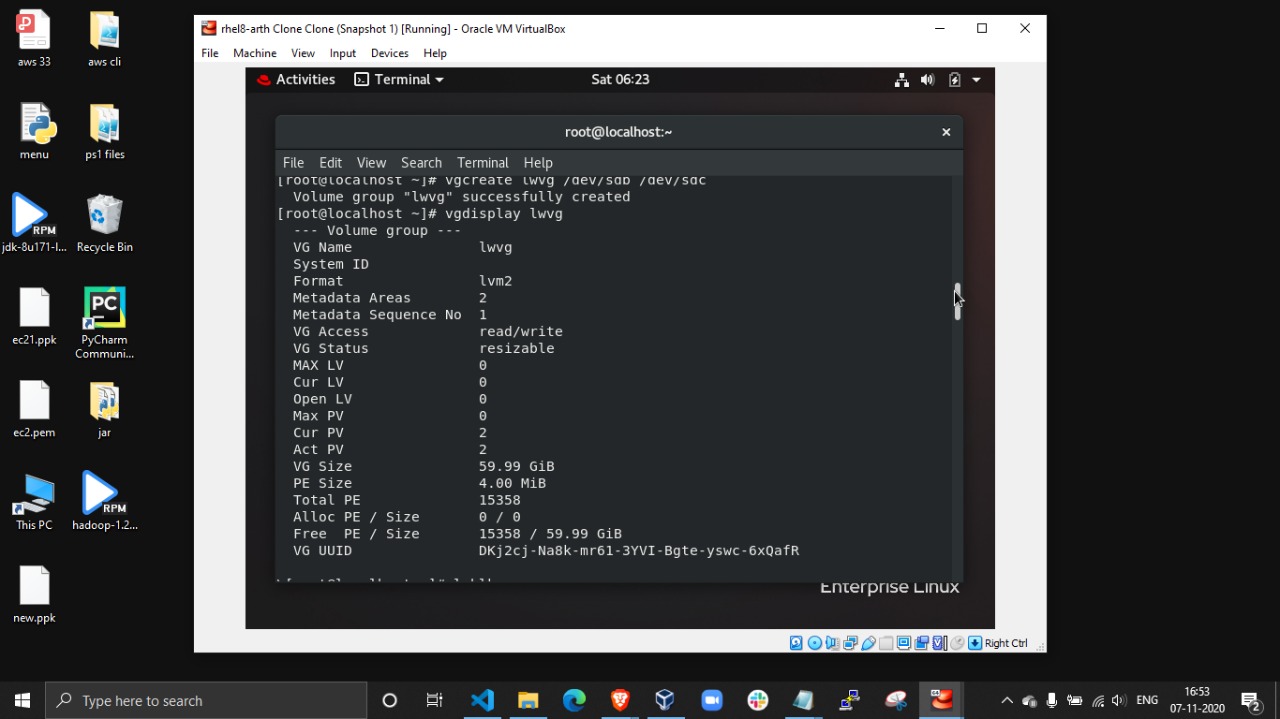
Then created lv(Logical Volume) using command lvcreate :
By using lsblk, we can check partitions created and their size on HD.
Here we can see that on both HD, lvm is created of size 52GB. That means we successfully created lvm.

using lvdisplay, we can check details of lv created:

Then we formatted the lv with ext4.
Then a folder /l1 created and mounted to the lv(mylv1)

Then using df -h command, we check lv created.
We can see that a lvm named lwvg-mylvl is created of size 51 Gib.
Step 2 : Integrating LVM with hadoop and provide elasticity to DataNode
For this, we created a hadoop cluster and set our Linux Os as datanode in which lvm created.
And in configuration file, lvm folder added ie. /l1

Using hadoop dfsadmin -report command, we can check the datanode of cluster and its storage.
In our datanode, we can see that its of around 50Gib storage that means its taking space from our lvm created.

Step 3 : Extend the size of DataNode on the fly without unmounting device.
Extended tha size of lv on the fly. added 5Gib.
In lsblk we can see that, in sdb and sdc both, lv size increased to 57Gib.


Using command hadoop fs -ls / , we can see our filed uploaded previously is still there, after increasing the size of LV.

We Integrated LVM with hadoop and provided elasticity to DataNode and Extended the size of DataNode on the fly without unmounting device. So Using LVM tecnique, we can increase the storage of device on the fly, without loosing data, without shutting down the system or unmounting the device.
Hope you liked my blog :)
 |



Comments
Post a Comment